

프로젝트
Stock Pyramid는 경매 이벤트의 대용량 트래픽을 처리하기 위한 node.js 기반
어플리케이션 시스템 구축 프로젝트입니다

keyword : #대용량 트래픽 처리 #검색 속도 향상 #성능 테스트 #nestjs #DB이중화
 기획 배경
기획 배경
대용량 트래픽 처리를 기술적 도전 과제로 삼은 이유
안정적인 시스템을 구축하는 일은 시스템의 신뢰성을 시험하고 평가하는 과정을 수반합니다. 평가를 위해 인프라, 네트워크, DB 등 다양한 요소를 고민하게 됩니다. 이러한 경험은 백엔드 엔지니어로서 기능 구현 뿐만 아니라 한 줄의 코드가 전체 시스템의 관점에 어떤 영향을 미치는지 종합적으로 판단하는 경험을 얻을 수 있는 최적의 프로젝트라 판단했습니다.
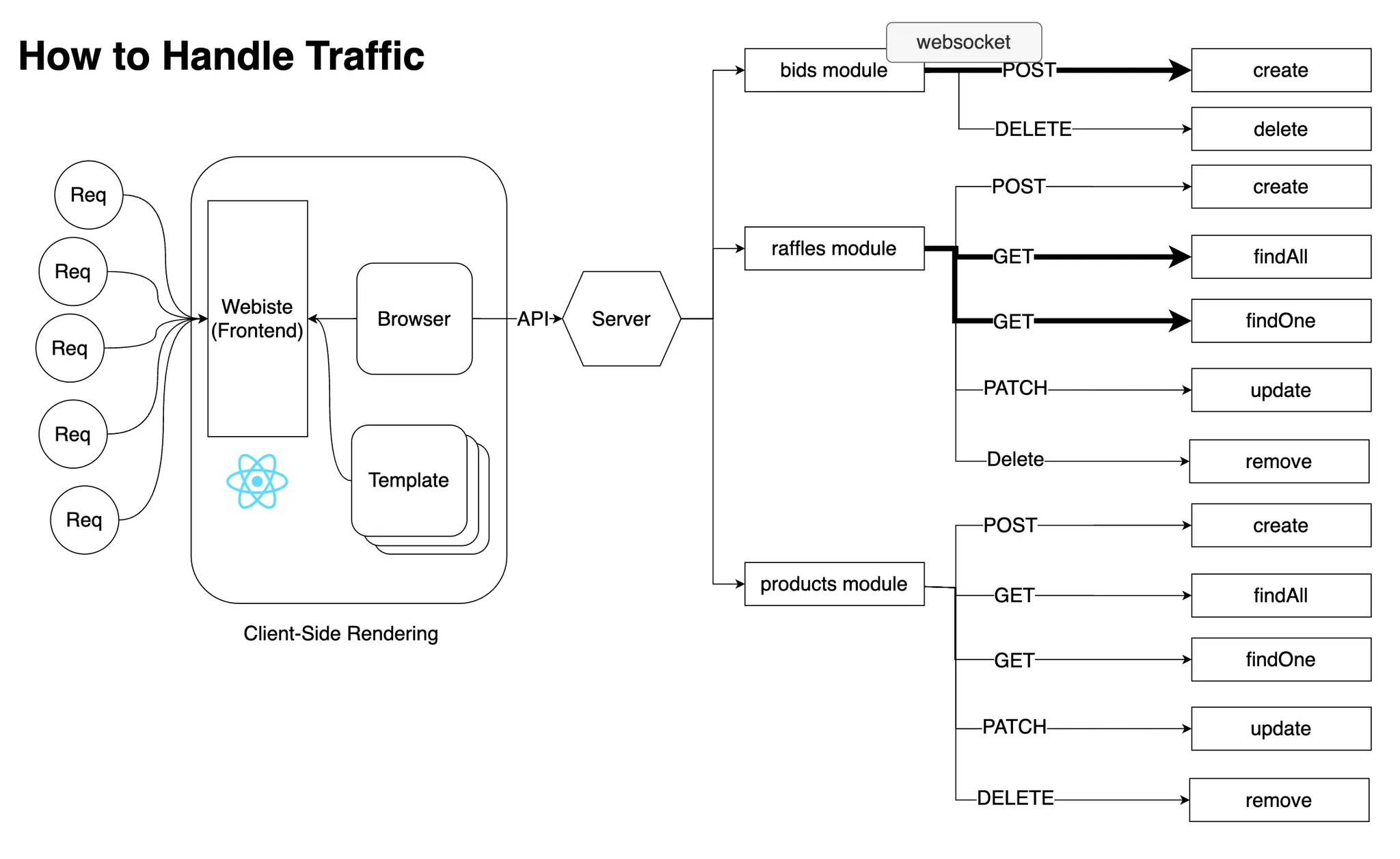
구현 API
•
생성
◦
입찰(bid) 제출
•
조회
◦
전체 : 경매(Raffle) 데이터
◦
상세 검색 : 사이즈 별 입찰(bid) 데이터
•
로그인
생성 데이터
•
테스트로 생성된 총 데이터량 약 1TB
•
경매 데이터(Raffle) : 1만
•
입찰 데이터(Bid) : 1,200만
•
상품 데이터(Product) : 1만
•
유저 데이터(User) : 20만
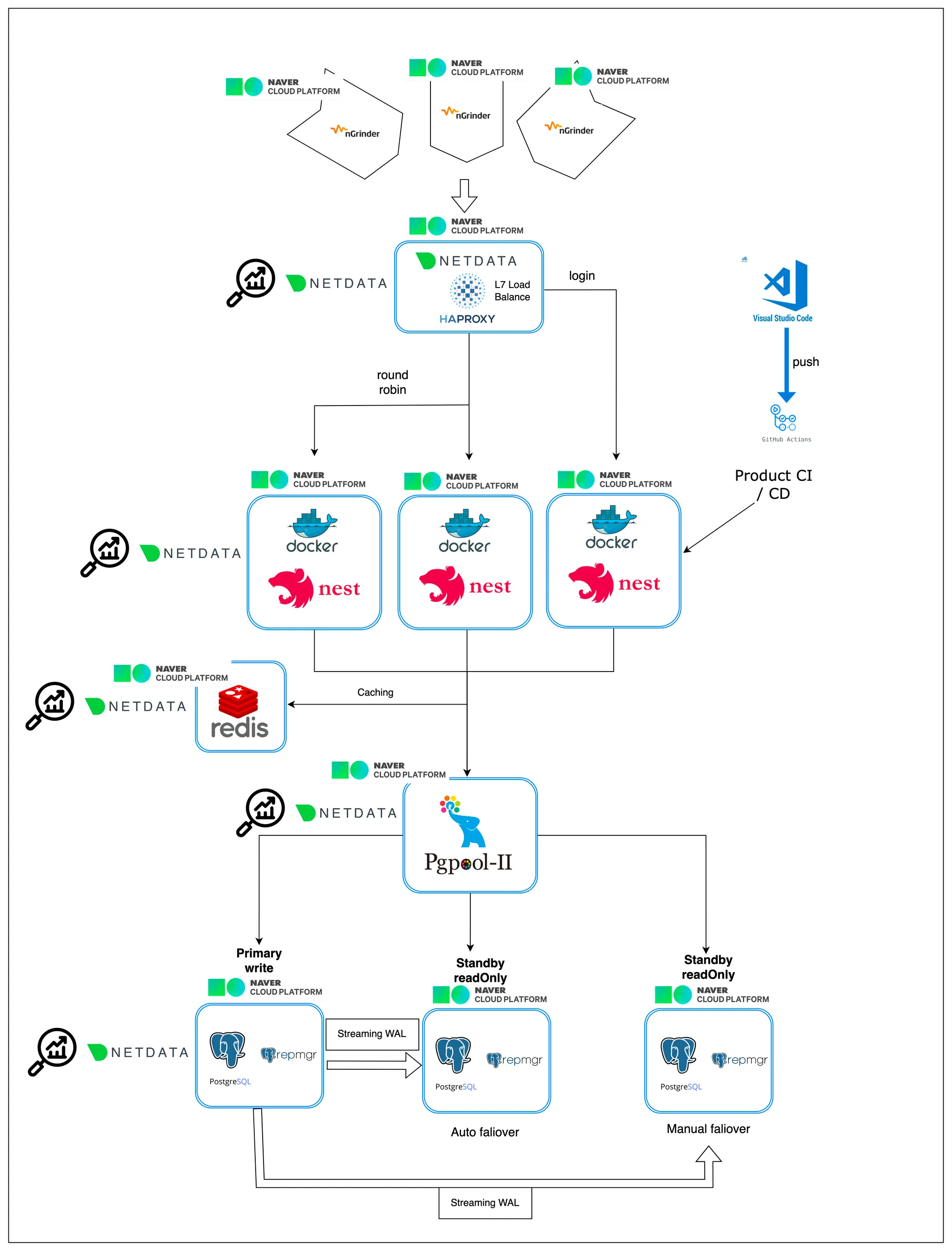
서비스 아키텍처 & 기술 도입 배경
프레임워크(nest.js)
•
옵션 : nest.js, express.js
•
선정 이유 : 협업 시 일정 수준 이상의 코드 표준화를 달성하기 수월하다고 판단
테스팅 툴(nGrinder)
•
옵션 : AB, Artillery, JMeter, nGrinder
•
선정 이유 : 복수의 머신으로 부하 테스트를 진행하고 상세 리포트 제공
모니터링 툴(netdata)
•
옵션 : New Relic, netstat, htop
•
선정 이유 : 오픈소스이고 성능 지표가 상세하며 도입 시 복잡한 절차가 필요하지 않음
요청 로드밸런싱 (HAProxy)
•
옵션 : nginx, apache, Cloud Load Balance Service, HAProxy
•
선정 이유 : L7 Load Balance 가 가능하여 특정 요청처리를 원하는대로 할 수 있음
•
원하는 곳에 설치하여 클라우드 로드밸런서 보다 실시간 모니터링이 쉬워짐
DataBase HA (repmgr)
•
옵션 : pg-pool II, repmgr
•
선정 이유 : Auto Failover 및 이중화 구성에 있어 메뉴얼 구성에 대한 접근방법이 다양함
DataBase Query Load Balance (pg-pool II)
•
옵션 : Cloud Service, pg-pool II
•
선정 이유 : 클라우드 서비스 보다 실시간 리소스 사용률에 대한 모니터링 및 가능해짐
기술적 도전 및 트러블 슈팅
DB 이중화를 통한 high available 및 Read/Write 속도개선
•
같은 OS 에서도 기존에 성공했던 절차를 따라 설치 및 세팅을 해도 실패하는 경우가 발생함
•
같은 centOS 7 에서도 컴퓨터 제공 옵션마다 설치 후 시스템 사용 가능여부가 달라짐
•
Naver Cloud Server 옵션중 Compact는 실패 High CPU 에서는 성공 Standard 에서는 실패
Postgres Index를 적용하여 검색 속도 개선
•
입찰 데이터를 검색 시, 기존 1,200만건의 입찰 데이터를 bidSize = 270 , order by createdAt 두 조건으로 full scan하고 있던 상황
•
bidSize 와 createdAt 두 컬럼에 인덱싱 적용 후, 응답 시간이 기존 700ms에서 100ms으로 약 85% 감소
•
단, 쿼리 실행 계획과 실제 요청 시 Latency의 변화 폭이 차이가 있었다는 점이 특이사항
Redis 캐싱
•
Raffle 전체 조회 API의 경우, 동시 접속자 수가 증가함에 따라 반복적인 I/O 작업으로 인한 병목이 발생
•
동일한 결과를 반환하고 데이터 휘발의 걱정이 없는 전체 조회 결과의 경우 캐싱을 하는 것이 적합하다고 판단
•
처음 실시간 모니터링 기능을 제공하는 Redis cloud을 도입했으나, 테스트 부하의 강도가 증가함에 따라 리소스 부족 현상이 발생하여 로컬 Redis로 변경
Github Actions - Docker Compose 활용한 CI/CD 파이프라인 구축
•
코드의 변경 사항이 있을때 마다 git push/pull을 하거나 docker 이미지를 만들고 pull을 받는 과정에서 피로도를 느낌
•
자동화를 하기위해 가장 잘 알려진 방법인 github Actions와 docker compose를 사용함
•
c6g 시리즈로 서버 구축시 cpu아키택쳐 문제로 도커이미지 빌드시 platform을 linux/arm64지정해줘야하는데, 그것떄문에 빌드하는데 시간이 오래걸림
•
platform에 따라 다른 방법을 찾아봐야한다(aws 코드디플로이 등등)
(현재 프로잭트에서는 금액 문제로 ncloud로 바뀌게되어 아키택쳐로인한 문제는 해결됨)
Performance Test 디자인
•
성능 테스트 실험 시, 실험 조건과 변수를 어떻게 설정해야 유의미한 인사이트를 얻을 수 있을지 고민함
•
Vuser, Agent, 서버 성능, 수평적 확장 여부 등을 주요 변수로 삼고 이를 평가하는 지표를 Throughput, Latency, 테스트 성공/실패 여부 등을 참고
대용량 트래픽이 서버에 끼치는 영향에 대한 테스트
부하에 대한 신뢰도 검증 Level Test 진행
•
레벨별 테스트를 진행하여 어느부분에서 병목이 진행되는지 파악이 가능해짐
•
level 1
◦
Instance Test
▪
nginx를 사용하여 기본 정적페이지 반환 테스트
▪
테스트 목적 : 현제 인스턴스의 컴퓨팅 스팩에서 최대 얼마만큼의 요청까지 처리할수있는지 확인
•
level 2
◦
Web Application Server Test
▪
‘hellow world’ 반환하는 testApi 만들어서 GET요청
▪
테스트 목적 : 기본적인 NestJs서버의 부하 수용 능력 확인
•
level 3
◦
Read Only Database Test
▪
프론트엔드에서 요청할 경매 데이터 1만개 GET요청
▪
테스트 목적 : nest서버와 데이터베이스와의 부하 수용 능력 확인
•
level 4
◦
Write Only Database Test
▪
6000명 vuser가 명당 1000번씩 총 6,000,000개의 POST요청
▪
테스트 목적 : 대량의 post요청시 데이터유실없이 디비에 잘 들어가나 확인
•
level 5
◦
Write / Read database Test
▪
agent1 = post, agent2 = findAll(with Redis), agent3 = findOne 동시 진행
▪
테스트 목적 : read,write동시 진행시 부하 수용 능력 확인
•
level 6
◦
Scenario Test
▪
agent1 = login→ findAll→ findOne → POST → findAll … 복합요청
▪
agent2 = POST (Random Interval Pattern)
▪
agent3 = findAll, findOne(Random Pattern)
▪
테스트 목적 : 실제 유저의 사용에 대한 부하 수용 능력 확인